논문 이전에
DD3D의 정식 논문 이름은 DD3D(is pseudo-lidar needed for monocular 3d object detection?)이다. 이는 기존 존재하는 논문 pseudo-lidar needed for monocular 3d object detection에 대해서 더 나은 발전 방향을 가지고 만든 논문이다.
그렇다면 기존 논문에 대해 요약한다면
pseudo-lidar란?

저렴한 센서인 카메라는 깊이 정보의 부재로 3D object detection에 낮은 정확도를 가진다. 하지만, 이 논문은 낮은 정확도의 원인은 camera 의 depth 정보가 아니라 데이터의 대표적인 문제라고 생각한다.
그.래.서
image로 depth map을 만들고, 이를 pseudo-lidar로 lidar 신호와 비슷하게 데이터를 생성했다. 이를 이용하여 3D object detection을 한다면 기존의 카메라의 대표적인 문제가 생기지 않을 것이라고 생각했다.
즉, 기존의 이미지를 다음과 같이 pseudo-lidar로 바꾼 것이 결과가 좋더라~ 는 내용이다.
논문이 제시한 문제점
이전 모델의 방식을 잠깐 언급하자면
- stereo나 monocular image를 이용해서 depth map을 estimation하고 depth map으로 back projection 시켜
Pseudo-LiDAR point를 얻습니다. - 얻은 Pseudo-LiDAR point로 LiDAR-based detector에 넣어서 3D bbox를 예측합니다.
하지만 이전 모델을 이러한 문제점이 존재한다.
- 1. 기존 3D object detection에 사용하던 Pseudo-Lidar 방식은 복잡한 학습 과정을 필요
→ Optimization(최적화)가 어려워 일반적인 성능이 떨어지는 문제점을 지님 - 2. depth 추정에서 생기는 에러가 결과 성능의 하락에 주요한 원인
그리고 다음과 같은 해결방안을 제시한다.
논문 해결 방안
- End to End 학습 방식의 모델을 제안하여 전반적인 성능을 높임
- dense한 깊이의 pre trainin을 통하여 추정 에러를 줄이고, 이를 통해 결과 성능을 높이고자 함
간단하게 기존 학습 방법과 문제점을 요약한다면
→ single image를 monocular depth estimation model을 통하여 depth map 얻음
→ 해당 depth map과 intrinsic matrix를 사용하여 Pseudo-Lidar 생성
→ single image을 2D object detection model을 사용하여 2D proposal 생성
→ Pseudo-Lidar과 2D proposal을 이용하여 3D object detection 모델 생성
즉 매우매우 복잡하다.
이에 대해서 위 논문은 다음과 같이 제시한다.
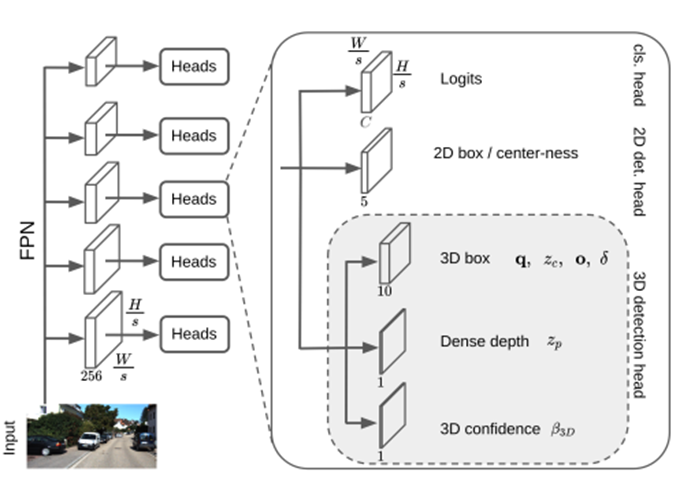
모델 구조는 fully convolution 구조를 지니며, multi-scale feature를 사용하는 FPN 구조이다.
- 이 때 FPN이란 Feature Pyramid Network로 Top-down 방식으로 CNN 자체가 레이어를 거치며 피라미드 구조를 만들고, forward를 거치며 더 많은 Semantic을 가지게 되는 것이다. 즉, 각 레이어마다 예측을 진행하여 Scale 변화에 더 좋은 모델이다.
- FCOS란 Fully Convolutional One-Stage Object Detection로, 바운딩 박스의 4명으로부터의 중심점을 예측, 각 회차 마다 거리를 제한하여 detection을 진행한다.
하나의 Back bone-network를 지니고, 3개의 sub-network 를 가진다.
- Back bone-network란? : 객체 감지, 객체 분할 등 task에 따라 이러한 모델의 구조를 지칭하는 말은 조금씩 차이가 있지만 비전에서 분류, 객체 감지 등 다양한 분야에 사용되는 특징 추출기를 백본 네트워크(backbone network)이라고 부른다
모델 해석
- cls(classification) head
- 2D detection head
- 2D box(bounding box와의 중심 거리를 의미)
- 3D detection head
- q (W, X, Y, Z) : 물체를 quaternion을 이용하여 표현한다.
- o : 3D box center offset
- multi-schale을 사용함으로 기존 해상도로 늘린다면 box center가 정확하게 돌아가지 않기 때문에 이를 도와주는 역할을 한다.
- δ : 3D object size
- 각 class 별로 object size의 평균값에서 편차를 구해 size를 정확하게 측정할 수 있게 해준다.
- Z_p : Dense Depth
- depth에 대한 에러로 인해 성능이 떨어지는데 이를 위해 dense depth를 예측하여 3D detection 성능을 높인다.
- B_3D : 3D confidence → 모델마다의 신뢰도
결론
- 기존에 존재하는 복잡한 Pseudo-lidar에 대한 해답을 얻었으며, 결과적으로 더 좋은 성능과 빠른 연산을 지닌다.
- 기존 Pseudo-lidar에 대해서는 in-domain pre-train을 하지 않았다면 많은 성능 하락이 존재하였다. 하지만 DD3D는 pre-train을 하지 않아도 더 높은 성능을 지니고 있다.
즉, 더 높은 성능과 더 간편해진 방식을 통해 빠른 연산이 가능하다.